



由國家高速網路與計算中心(NCHC,國網中心)及 NVIDIA 和 OpenACC 共同舉辦的「2025 NCHC Open Hackathon」(Open 黑客松)競賽,本年度再次匯聚了傑出學者及頂尖機構團隊,利用各種最新的程式設計模型、函式庫和工具,大大加速 AI 與高效能運算(HPC)的研究成果。
本屆黑客松延續「突破自我」的核心精神,在為期三週的時間內,由參賽團隊自訂主題,涵蓋當今最新熱門的先進研究包括 AI 於大氣科學、量子化學、電腦視覺等領域,並藉由各組導師 (Mentor)與學員間的協作討論,深度探索從傳統 CPU 轉移至新世代 GPU 軟硬體技術如何加速其研究架構的無限可能。
同時,本屆活動也特別邀請了歷年來提供 Open 黑客松活動 GPU 技術支援與導師團隊的背後推手- OpenACC 黑客松技術籌備主管也是 NVIDIA 技術計畫經理 Bharatkumar Sharma 特別來台,參與活動最受矚目的入選團隊綜合簡報,見證各參賽團隊因新技術採用而獲得的研究進展,為活動劃下精彩的句點!
高速運算驅動「量子神經網路預測颱風」與「大氣模擬計算器」應用
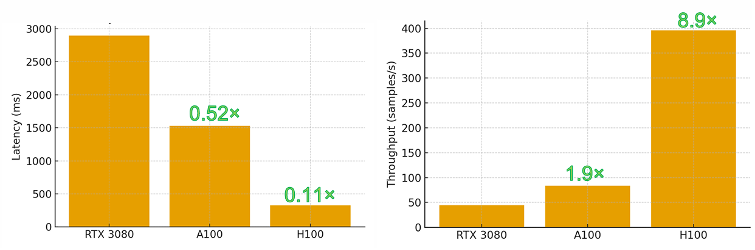
「Open 黑客松讓我們可以帶著極具挑戰性的題目,獲得專家指導的新一代 GPU 軟體技術與強大算力的支援。」由中原大學電機工程學系教授洪穎怡實驗室組成的「CYCU Power Lab」專注研發颱風預測及風電場風險評估系統,應用範疇涵蓋颱風路徑、半徑、強度、風速預測,以及風電場渦輪機運作狀態的評估。CYCU Power Lab 團隊表示,傳統的數值天氣預報(NWP)在處理風電場所需的逐時精確預測上仍存在落差,透過 Open 黑客松,CYCU Power Lab 嘗試利用「NVIDIA GeForce RTX 3080」、「NVIDIA A100 Tensor Core GPU」和「NVIDIA H100 GPU」,測試一種混合式架構 ── 結合深度學習模型 TFT (Temporal Fusion Transformer)與變分量子子網路(QLSTM mixer),觀察量子非線性是否有助於處理極端風險(tail risks)與不確定性。 同時,CYCU Power Lab 在各款 GPU 實驗 BF16/TF32 精度,並採用一系列 NVIDIA 解決方案加速 Flash/SDPA 注意力機制、torch.compile 與融合優化器(fused optimizers),也藉由 NVIDIA CUDA-Q 完成批次量子運算。CYCU Power Lab 分享,「針對加速成果,我們將模型訓練時間從超過 3 天減少至 4 小時,訓練吞吐量更從 RTX 3080 的每秒 0.19 次迭代提升至 H100 的 1.70 次,實現近 9 倍的效能提升。這些進步讓我們能建立一個『利用過去 72 小時的數據預測未來 24 小時數據』的流程,並在每小時更新一次,這對於風電場的停機規劃與營運決策具有高度實用價值。」
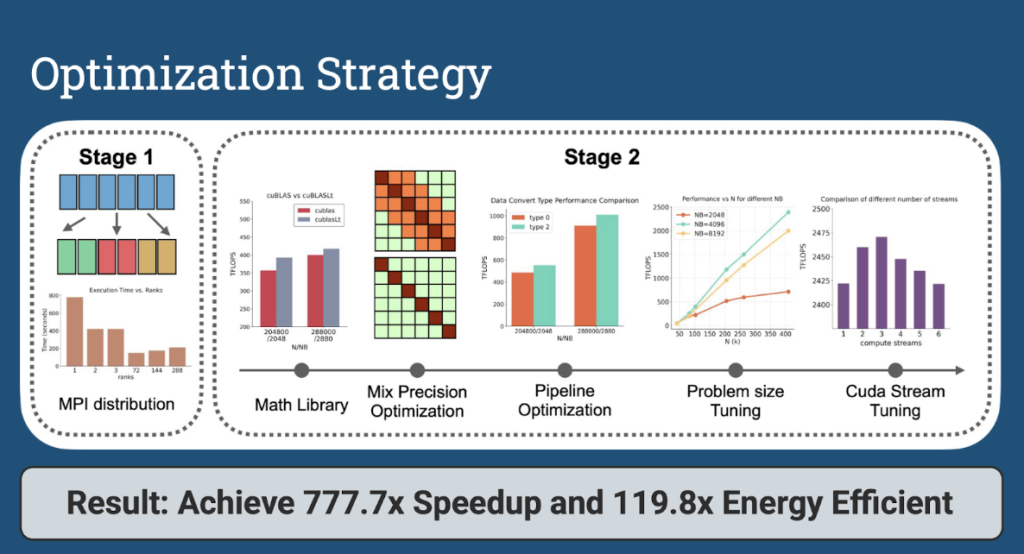
台大資訊工程學系教授李濬屹組成的「Usagi」團隊聚焦新一代高解析度氣候模擬技術「Exascale climate emulator」,以 GPU 混合精度運算與分散式架構,大幅縮短模擬時間,達到 exascale(百億億次運算)級效能,並在本次黑客松取得 777 倍的加速,解決過去氣候模擬達到精確的全球規模,往往需要耗時數月才能完成運算的龐大挑戰。Usagi 團隊指出,參加黑客松之初,成員們對於 NVIDIA CUDA 與系統分析工具並不熟悉,透過與 NVIDIA Mentor 每週一次的小組報告和密集實作指導,團隊發現程式中的漏洞與 GPU 平行度不足的問題,成功找出優化方向。除了運算效能的提升,Usagi 團隊在能源效率(Energy Efficiency)的表現更為耀眼,根據團隊統計,優化後的大氣模擬計算器在能源消耗上節省高達 119 倍,可以減少 5,056 公噸二氧化碳,換算為具體指標,相當於 1,091 輛汽車行駛一年的排放量,或是 83,571 棵樹在十年內才能吸收的總碳量,這證明高效能運算不僅加速科學發現,更是推動環境永續的關鍵技術。
從量子分子生成模型到電漿模擬,借助 CUDA-Q 等 GPU 軟體技術助攻前瞻創新研究
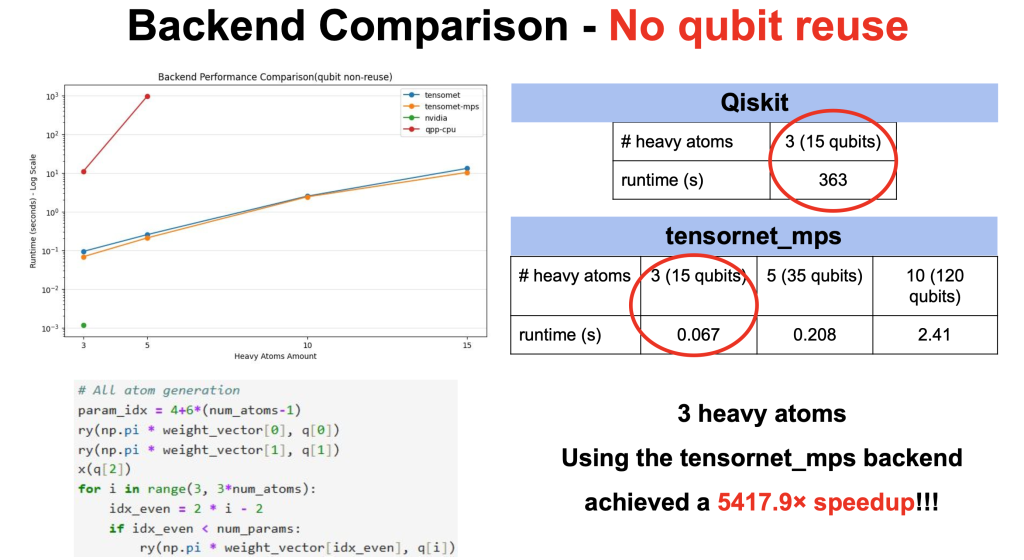
由成功大學材料科學及工程學系教授陳雨澤和亞洲大學生物資訊與醫學工程學系教授吳家樂帶領的「Qa-MolGen」團隊,展現量子分子生成模型在材料科學領域的巨大潛力。Qa-MolGen 團隊指出,量子分子生成模型仰賴重元素,不過當重元素的數量增加,會導致模型運算成本呈現指數型上升,因此 Qa-MolGen 團隊使用 NVIDIA CUDA-Q 軟體工具,幫助模型推論更有效率。另一方面,Qa-MolGen 團隊的量子分子生成模型採用 qpp-cpu、NVIDIA、tensornet 三種後端(Backend),成員們也透過 NVIDIA CUDA 測試模型運行的規模和程度,「我們發現 qpp-cpu、NVIDIA Backend 較適合用於小規模的模型訓練和推論,所以在最後使用 tensornet,並實現將量子分子生成模型加速 5417.9 倍的具體效益。」Qa-MolGen 團隊說明,量子分子生成模型就像「材料科學的 Google Map、導航器」,使用者只要提供條件,模型就能協助找到更適合的材料,這幫助科學家在數千萬種材料中更精確搜尋目標,減少大量實驗的成本,未來,團隊也將會持續提升分子生成的有效性及獨特性。
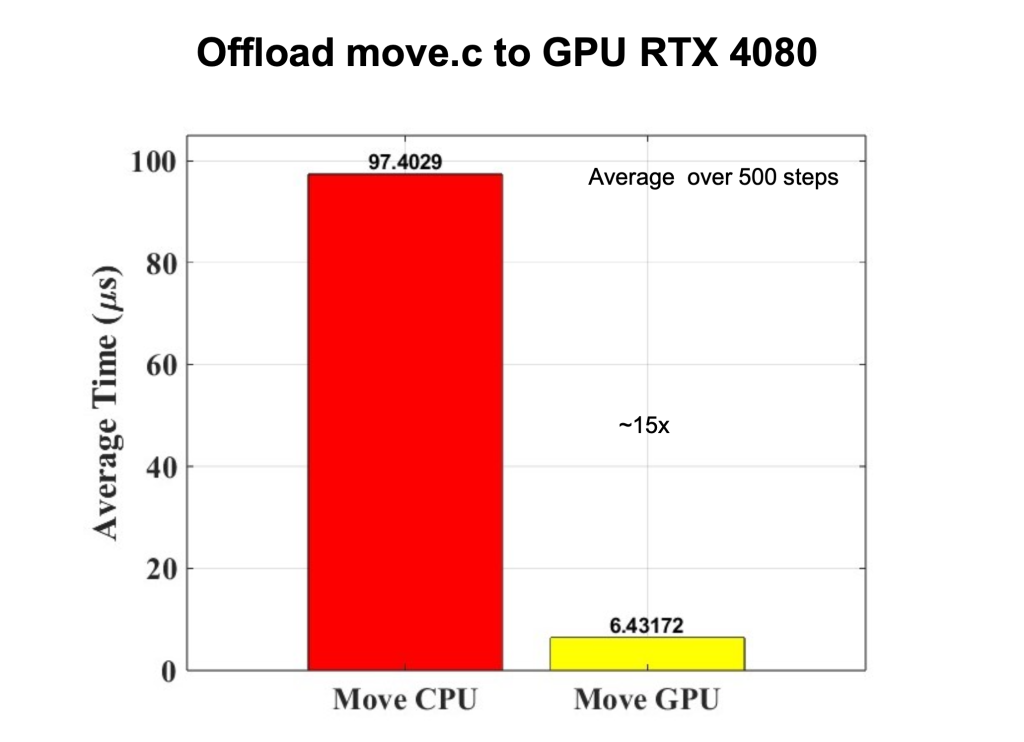
「我們希望參加此次黑客松,利用最先進的 GPU 效能及軟體技術提升 PIC-MCC 模擬速度,」由台北科技大學機械工程系教授林銘杰帶領的團隊「PTSG Taiwan」主要進行電磁/電漿模擬,並使用由電漿理論與模擬小組(PTSG)開發的粒子網格(PIC)蒙特卡羅碰撞(MCC)程式套件。PTSG Taiwan 團隊在 Open 黑客松,學習透過 NVIDIA Nsight Systems 分析各項 PIC 演算法在 CPU 上的計算效率,並在 NVIDIA Mentor 的建議下使用 OpenACC 進行 Offload,了解各演算法在 GPU 上的加速潛力,更成功開發新的 GUI,讓整個 PIC 迴圈計算可以 Offload 至 GPU,避免計算儲存延遲。參賽過程中,PTSG Taiwan 團隊的關鍵收獲,不只是學習 NVIDIA 程式工具、函式庫的應用,也發現 PIC 幾個重要演算法確實可以在 GPU 上以雙精度有效加速 15 倍以上,高於最初的預期,後續,團隊將使用 NVIDIA CUDA 來開發整個 PIC 演算法提升效能,同時與 NVIDIA AI Research Center 合作推進計畫,目標為半導體電漿製程提供最佳模擬平台。
深化「無人機影像」、「3D 人體姿勢重建」的電腦視覺應用
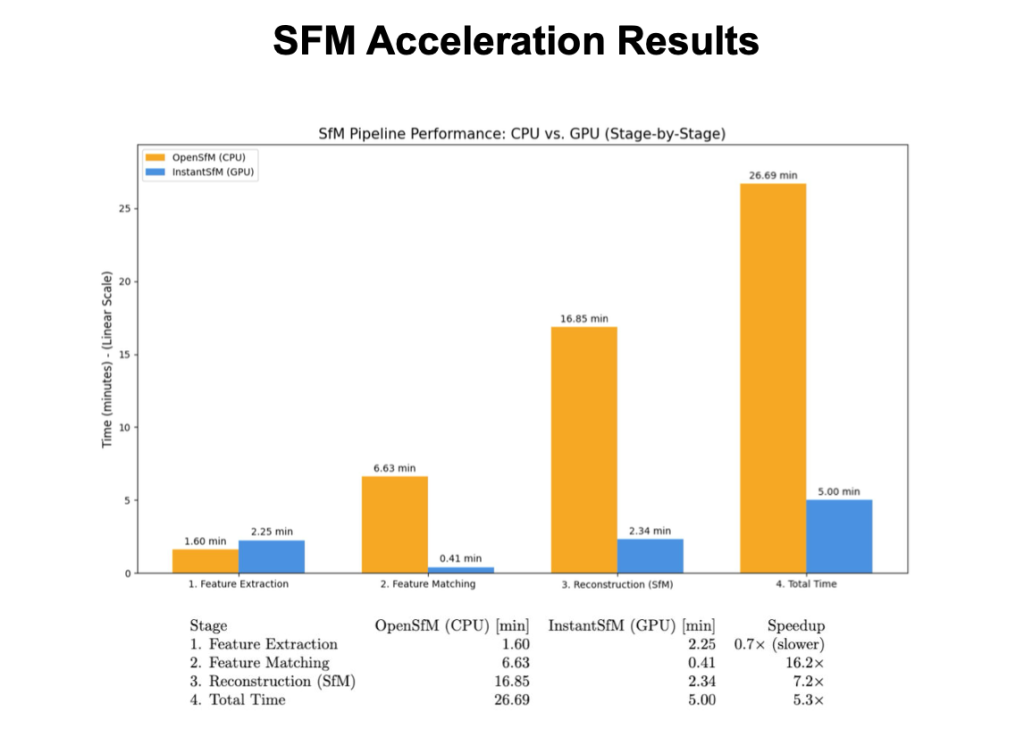
隨著無人機應用範圍逐漸擴大,如何將數百張甚至數千張的高解析度照片快速合成為一張完整的全景圖或 3D 模型,成為一項關鍵技術。Ndvignition 團隊來自清華大學資訊工程學系教授黃能富帶領的高速網路實驗室,他們指出傳統拼接技術主要仰賴 CPU 運作,但 CPU 一次能處理的資料量有限,可能導致運算流程非常耗時,難以滿足即時處理的需求。在使用 NVIDIA Nsight Systems 分析工具和日誌追蹤後,Ndvignition 團隊發現傳統 WebODM 的重建流程計算量集中於 OpenSfM,便將原本在 CPU 上執行的運算負載遷移至 NVIDIA A100 GPU,也導入 GPU 平行化的 InstantSfM,只計算真正有關聯的部分,大幅加快求解速度。而經過實際測試,團隊將整體處理時間從一小時縮短至大概 20 分鐘,這項影像加速技術將能助力使用者在農地調查中,以無人機快速生成大面積土地的全景圖以供分析;在災害評估或戰場偵察等緊急情況下,也可以協助前線人員拍攝照片,迅速合成可供決策的關鍵影像,「在參與黑客松的過程中,NVIDIA Mentor 特別和我們一起優化報告方式,將艱澀的技術詞彙轉化為易於理解的表達,讓研究成果能更有效地被外界理解。目前,團隊深入掌握高效能運算的開發邏輯,未來也將持續優化影像處理精準度,並應用於更多 3D 重建與 AI 相關研究。」
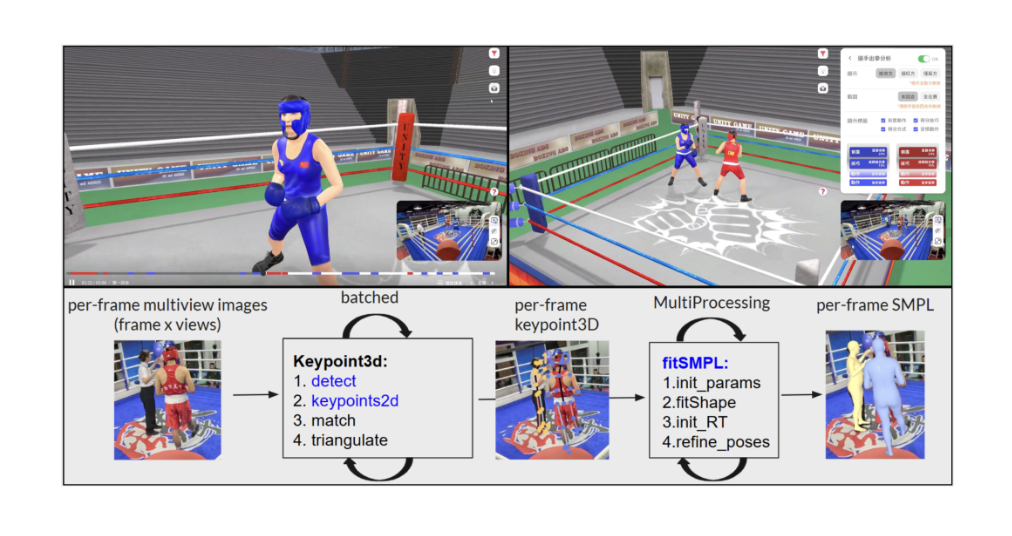
「NVIDIA Mentor 協助我們的地方,就是透過效能分析幫助團隊找出真正問題點,再引導我們調整研究方向,」由清華大學資訊工程學系教授朱宏國和胡敏君共同帶領的「Paw Patrol」團隊將 3D 人體姿勢重建加速 8.5 倍。在黑客松初期,Paw Patrol 團隊已經完成 view-axis 的批次(Batch)推論,將同一時間點下的多視角影像一起送進 GPU 進行推論,這個方法帶來一定程度的改善,但因為實驗資料通常只有 3 到 4 個視角,批量大小(Batch Size)很快就受到限制,GPU 也仍然存在明顯的待工時間(idle time)。在 Paw Patrol 團隊原先規劃的下一步,是從模型本身出發,透過縮小網路架構或調整模型設定加快單次推論的速度,NVIDIA Mentor 建議團隊先使用 NVIDIA Nsight Systems 對流程 (Pipeline)進行完整分析,「所以我們和 Mentor 一起檢視 GPU 的時間軸,逐段分析 detect 與 keypoint2D 的執行方式,並對照 GPU 使用率與各階段出現閒置的情況。」透過共同分析的過程,Paw Patrol 團隊發現即使模型本身已經相對高效,整體流程仍然是以 sequence per subject 的方式 sequential 地執行,導致不同時間點之間無法有效累積 Batch,這才是效能無法再進一步提升的主要原因。在 Mentor 的協助下,Paw Patrol 團隊決定暫緩模型層面的優化,改為從系統架構出發,重新設計推論流程,將原本僅限於 view-axis 的 Batch,進一步擴展成 time-axis 的 batch 推論,一次同時處理多個時間點與多個視角,Paw Patrol 團隊強調,「這樣的調整讓批量大小不再受限於視角數量,大幅降低 sequential inference 之間產生的 idle time,也直接促成 detect 與 keypoint2D 超過 10 倍以上的加速成果,成為整個研究推進過程中最關鍵的轉折點。」
NCHC Open Hackathon 旨在幫助開發者將各種研究架構,包括 CPU 和 GPU 上的 AI 及高效能運算專案加速和最佳化。同時,主辦單位根據團隊主題規劃配對程式設計導師或是在特定應用領域經驗豐富的專家,透過深度協作共同激盪創新火花,並協助團隊使用 NVIDIA 各種模型、函式庫和工具,制定更清晰的開發與加速藍圖,展開更先進卓越的研究內涵。
想瞭解本屆各團隊完整技術成果,請閱讀本文 >https://www.nchc.org.tw/Message/MessageView/4040?mid=46&page=1



