



Google 於 2025 年 10 月 7 日發表了一項革命性技術 Speech-to-Retrieval (S2R) 搜尋模型,徹底改變了以往的語音搜尋流程。在過去進行語音搜尋時,通常都需要先將語音轉換成文字(ASR,俗稱自動語音識別 Automatic Speech Recognition),再以文字進行搜尋。然而,在 ASR 過程中即使只是些微錯誤,也可能導致搜尋結果與預期大相逕庭。舉個例子,如果我們想搜尋”scream painting”這幅畫,但語音辨識時誤將 m 聽成 n,變成”screen painting”,那搜尋結果就會完全不同。
面對 ASR 準確性的局限,Google 想出了一種嶄新的做法:直接利用語音來進行搜尋,繞過轉成文字的階段。
因此革命性的技術 S2R 就誕生了。
S2R 的訓練原理:語音直接檢索文檔的模型架構
那 Speech to Retrieval 是怎麼被訓練的呢?
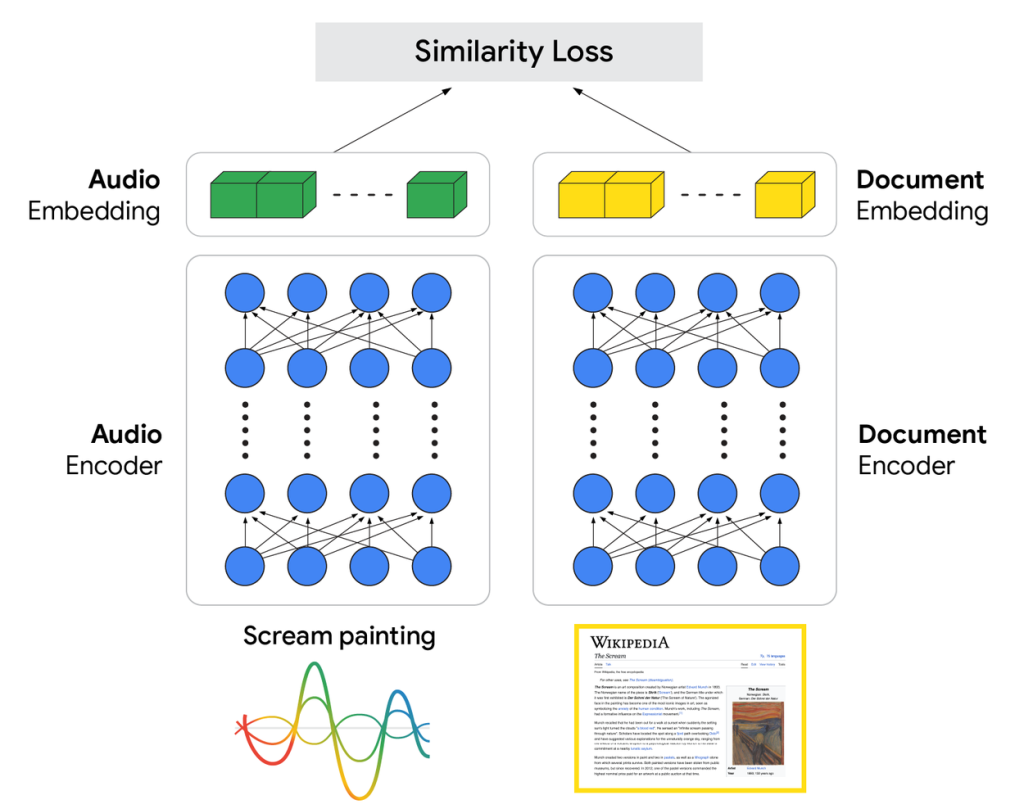
原理其實很簡單,首先,我們需要一個語音與文件的對應資料集。模型採用 dual-encoder 架構(見圖二):
- Audio Encoder:負責將語音轉成語音 embedding
- Document Encoder:負責將文檔轉成文本 embedding
在訓練時,每次將語音資料丟入 Audio Encoder,文件資料丟入 Document Encoder,兩邊各自經過 encoder 後,就會得到一組 embedding 向量後,接著計算兩個向量之間的相似度損失(similarity loss):
- 如果這組資料是正相關(語音對應文件),就希望兩者的向量越靠近越好
- 如果這組資料是負相關(不匹配),則希望兩者的向量越遠越好
計算完相似度損失後,再透過 backpropagation 將梯度傳回兩側的 encoder,更新模型參數。經過訓練後,語音與文件就被映射到同一個向量空間,可以直接用語音 embedding 去檢索文件 embedding,完成搜尋。
值得注意的是,S2R 的這種訓練方式,其實就是非常著名的對比學習(Contrastive Learning)。
透過對比學習的理念,我們能學到一個語意向量空間,把正樣本拉近、負樣本拉遠,而不需要依賴傳統的語音轉文字流程。
什麼是對比學習 Contrastive Learning?
對比學習(Contrastive Learning)的核心概念其實非常直覺:希望把相似的樣本拉近、把不相似的樣本拉遠,可以想像成在一個向量空間中,調整樣本之間的距離,讓相似的樣本靠得更近,而不相似的樣本保持距離。
對比學習最常見的應用場景就是訓練 embedding:透過這種方式,模型可以讓資料的語意或特徵關係自然地反映在向量距離上,並且得到的 embedding 可以應用在多種任務中,像是推薦系統、圖像分類等等。由於對比學習的架構發展是大同小異並且循序漸進的,接下來我們將介紹最早且最具代表性的對比學習架構之一—— SimCLR。
SimCLR:對比學習的里程碑模型
在對比學習的發展歷程中,2020 年提出的 SimCLR(Simple Framework for Contrastive Learning of Visual Representations)是一個重要的里程碑。
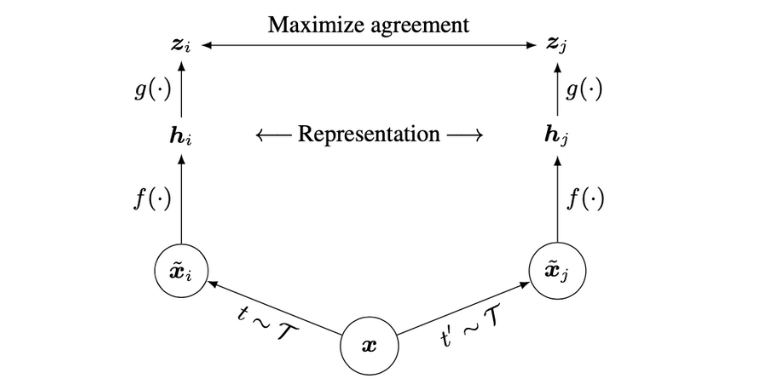
SimCLR 在模型架構是採用孿生網路(Siamese network)(見圖三),意思是使用兩個相同架構的神經網路,且兩者共享參數。至於 Loss function 的設計則採用 NT-Xent,目的是要讓相似的樣本能夠靠近,不相似的遠離。比較有趣的是,SimCLR 是一種 self-supervised 的 learning,以下我們將介紹他的訓練方法。
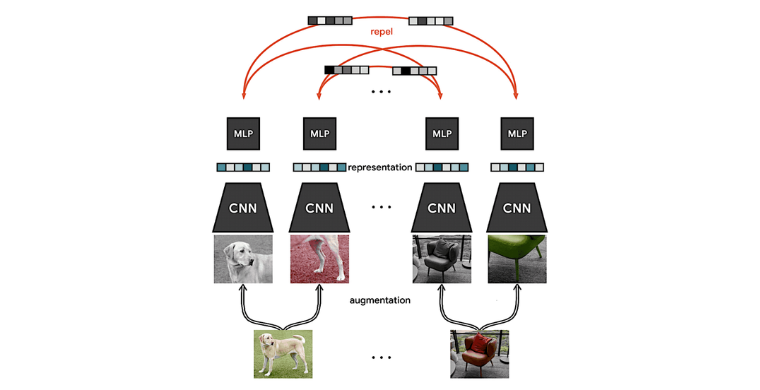
首先,我們會餵入一組圖片進去,每一張圖片都會先經過 data augmentation(例如:裁減、顏色變換)去產生出兩張圖片,接著會將他們各自餵入孿生網路的一邊,首先經過一層 encoder,接著會將其餵入一個 non-linear 的 projection head,而最終產生向量。經過這個過程會產生 2N 個向量(以圖四為例,N=2),而這時,由於我們必須要讓相近的樣本靠近,不同的樣本遠離,因此我們就需要正樣本以及負樣本。
在 SimCLR 中,正樣本很明顯的就是同一張圖經過 data augumentation 後產生的那一對圖。而這個方法,很聰明的將不屬於這一對圖的 2*(N-1) 張圖當成負樣本(以圖四為例,狗狗圖產生的那兩張圖,因為出處相同,他們是很相似的,因此為正樣本,反之,椅子的那兩張圖對於狗狗的圖而言不相似,因此為負樣本)。
接著對每個向量先去計算 cosine similarity,然後再將其套入 NT-Xent 去計算出這個正樣本對其中一邊的 loss,接著再將所有可能的正樣本對的損失加起來取平均,最後再利用這個 loss 去 backpropagate 回原本的 model(完整 algo. 請見圖五)。
SimCLR 實際應用:下游任務表現與訓練注意事項

介紹完訓練過程後,我們來說明應用方面,SimCLR 實際是利用其孿生網路的 encoder 去應用在下游的任務當中(例如:圖像分類),在當時的結果發現,如果我們把剛剛 pre-trained 得到的 encoder 加入下游任務中,不用額外加入 fine-tuning 的結果,幾乎就與直接在下游任務 supervised learning 的結果相同,並且如果有加上 fine-tuning 的話,出來的結果幾乎都會更好,這是一個非常大的好處,因為如此我們可以不用擁有這麼多的 label 資料,並且效果還會更好。
但有優點就一定有缺點,SimCLR 這個方法需要很多的負樣本,不然效果會顯著地變差,因此也意味著他需要很大的 batch size,而 batch size 也代表需要很大的 VRAM 才可以訓練,對 GPU 的消耗很大。另外,適當的 data augumentaion 也很重要,如果今天 augumentation 的品質不佳,也會很大的影響 SimCLR 的效果。
雖然 SimCLR 在架構上仍有一些不足,但它仍是對比學習的重要里程碑。後續許多研究都以它為基礎進行改進,例如 MoCo (Momentum Contrast for Unsupervised Visual Representation Learning)利用 momentum encoder 與 memory bank 降低了對大批次的依賴,而 BYOL (Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning)則移除了負樣本,透過目標網路與動量更新的設計讓訓練更穩定。這些改良使對比學習的應用更加廣泛,也奠定了後續多模態研究的基礎。
S2R 重新定義語音搜尋,對比學習成為關鍵技術基石
對比學習不僅推動了影像表示學習的革新,更為跨模態任務(例如 Google 的 Speech-to-Retrieval, S2R)奠定了堅實的技術基礎。S2R 成功證明了:藉由對比學習統一語音與文檔的語義空間,我們能有效地克服傳統 ASR 的錯誤,實現更精準、更穩健的端到端檢索。
S2R 的成功將加速語音應用領域的進化。我們可以預期這類基於語音-語義對齊的技術被廣泛應用於:
- 語音助理: 助理能真正理解「意圖」而非僅僅「詞彙」,無論使用者發音、口音或語境多複雜。
- 大規模數據的跨模態檢索: 例如在 Podcast 庫或影片庫中,用戶可以直接用語音查詢內容,即使關鍵字未被精確轉錄成文字也能找到所需片段。
- 設備的低延遲語音交互: 由於無需等待 ASR 完成,S2R 架構能實現在手機、穿戴裝置或 IoT 設備上即時且高效的內容檢索。
最後,隨著大型語言模型與多模態模型的融合,基於對比學習的 S2R 原理將更深入地整合語音、圖像與文字等多種模態,使模型能真正理解並統一不同感知來源的語義空間,朝向更全面、更智慧的下一代人機交互與表示學習邁進。



