



企業正在用 AI 加速業務,攻擊者也正在用 AI 加速攻擊,但大多數公司的資安防護可能還沒跟上,上篇我們談到 AI 如何讓駭客的速度快到傳統資安可能來不及反應,這一篇,我們要談解法,當你的公司已經、或即將部署 AI 代理人,有哪些防禦架構值得現在就放進開發清單?
Google 在今年 Cloud Next ’26 上提出了一套新的防禦思維,核心概念只有一句話:要對抗 AI 攻擊,防禦也必須是 AI,這篇文章整理了 Google 針對代理人安全的三層架構,以及開發者現在就能對照的實務檢查清單。
Google 解方:以代理人對抗代理人的三層防禦
面對這樣的全新攻擊面,Google 在 Next ’26 揭露的解法大概可以歸納為三個層次的防禦,分別針對「代理人本體」、「AI 應用」、「對外互動」,對開發者而言,這三層其實就對應到開發代理人時會碰到的三個階段:
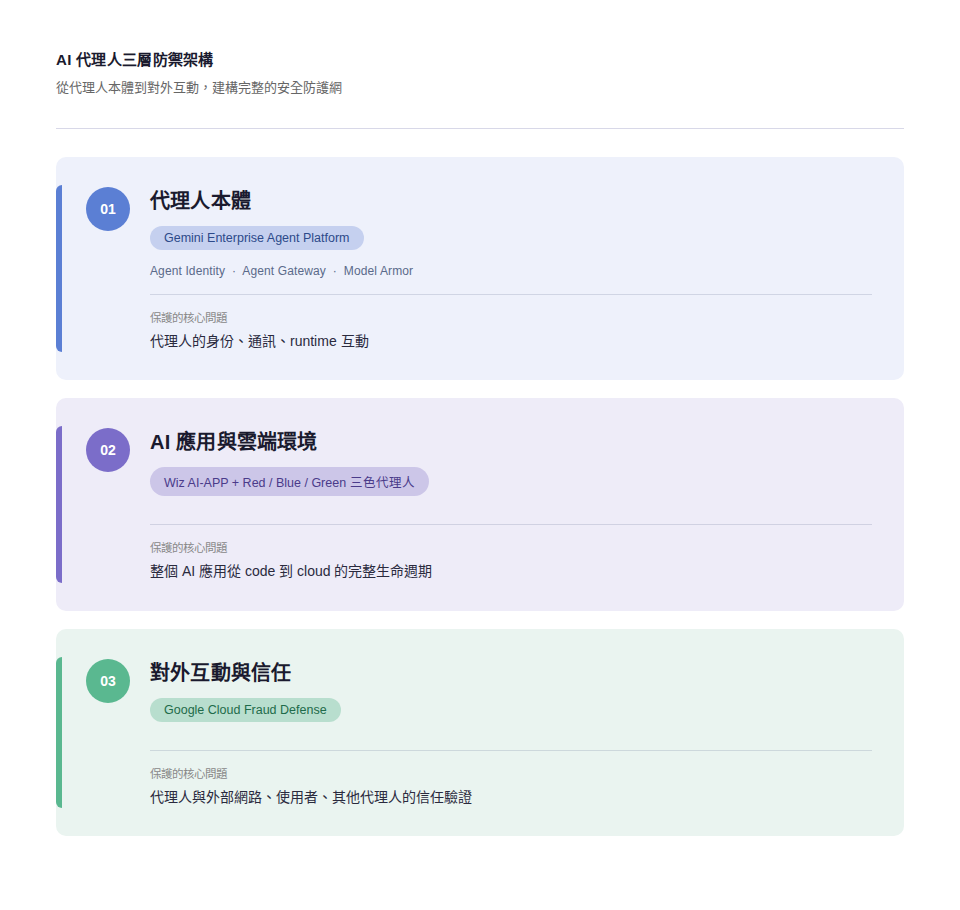
第一層保護代理人本體
這三個能力整合在新發佈的 Gemini Enterprise Agent Platform 裡,直接對應前面提到的「代理人身份、行為、模型層」攻擊面。
Agent Identity 為每個代理人建立獨特身份與認證流程,並支援帶有範圍(scoped)的人類委派,白話來說就是每個代理人都有自己的「工作證」,誰派它來、能做什麼、不能做什麼,全部有跡可循,這解決的是影子 AI 的治理問題。
Agent Gateway 則是代理人流量的統一閘道,能理解 MCP 和 Agent2Agent(A2A)等代理人協定,對所有 agent-to-agent 和 agent-to-tool 的連線做政策審查,換句話說,代理人每次對外「伸手」,都會先經過這道關卡。Model Armor 是運行時的即時防護層,專門攔截提示詞注入攻擊、工具投毒,以及敏感資料外洩。它現在已整合進 Agent Gateway、Agent Runtime、LangChain 和 Firebase,重點是不需要修改任何程式碼就能直接啟用,對已在開發代理人的團隊來說門檻非常低。
用 AI 守護整個 AI 應用環境
如果第一層是保護代理人「個體」,那第二層就是保護代理人所在的「整個應用環境」。這部分的主角是 Google 去年收購的雲端資安公司 Wiz,以及它今年推出的 AI Application Protection Platform(AI-APP)。
Wiz AI-APP 覆蓋 AI 應用的六個層次:基礎設施、資料、存取、模型、代理人、應用程式,從程式碼到 runtime 端到端保護。而這個平台最亮眼的發佈,是三個分工明確的 AI 資安代理人:
- Red Agent:扮演攻擊者角色,能在極短時間內分析應用程式的行為、即時調整攻擊手法,並驗證網頁應用與 API 的實際漏洞。簡單說,就是讓 AI 幫你先打自己一遍,提前找出破口。
- Blue Agent:負責威脅發生後的調查與應變,會整合雲端監控數據、運行時訊號、身份識別等資料,完整還原事件經過並評估嚴重程度,讓分析師能夠快速理解並採取行動。
- Green Agent:聚焦在問題的根本修復,像一位資深資安工程師,整合 Security Graph、code-to-cloud 關聯、身份歸屬、歷史修復模式,找出真正的根因並給出具體修復步驟。
對開發者來說還有一個好消息:Wiz 現在已支援 AWS Agentcore、Gemini Enterprise Agent Builder、Microsoft Azure Copilot Studio、Salesforce Agentforce 等主流代理人開發平台。不管你的團隊用哪家工具建構代理人,都能直接納入 Wiz 的保護範圍,不需要另外整合。
另一個實用的新功能是 AI-BOM(AI 材料清單)。就像製造業會列出產品的零件清單,AI-BOM 會自動盤點你的環境中所有正在使用的 AI 框架、模型與開發工具外掛,讓你清楚掌握哪些是公司核准的工具(例如 Gemini Code Assist、GitHub Copilot),同時揪出未經授權、私下在跑的影子 AI 外掛。
Fraud Defense,為代理式網路建立信任層
前兩層處理的是「你家內部」的代理人,但代理式網路(agentic web)的終極場景是:代理人會跑到其他公司的網站、API、服務上完成任務。這時候新的問題來了:對方怎麼判斷「這個代理人是授權的好代理人,還是惡意代理人」?
Google 的答案是 Cloud Fraud Defense,可以理解為 reCAPTCHA 的進化版,過去 reCAPTCHA 負責辨別「人 vs 機器人」,現在 Fraud Defense 要多處理一個維度:「授權代理人 vs 惡意代理人」,它提供了三種能力:
Agentic Activity Measurement:整合 Web Bot Auth、SPIFFE 等業界標準,辨識、分類、分析代理人流量,並把代理人身份與人類身份串連起來,讓每一筆代理人行為都有人可以負責。
Agentic Policy Engine:讓網站管理者能依據風險分數、自動化類型、代理人身份,針對不同階段的使用者旅程設定允許或阻擋政策。
AI-Resistant Challenge:當偵測到疑似惡意行為時,啟動新的 QR code 挑戰,要求人類介入驗證。這種挑戰是設計來讓自動化詐騙在經濟上變得不划算。
Google 強調,Fraud Defense 的信任資料來自保護 50% 的 Fortune 100 公司與超過 1,400 萬個網域的情報網絡,並且在帳戶盜用(ATO)場景中平均降低 51%。對於要把代理人送出去跑的企業,這是一張必要的信任通行證。
對開發者的意義:設計代理人時,請把這四件事放在清單上
看完 Google 整套防禦架構後,你可能會想:「這些產品看起來都很強,但我現在正在開發的代理人該怎麼用?」以下是從這次發佈整理出的四個實務檢查點,不管是在任何平台上開發,都值得優先想清楚:
- 代理人有身份嗎?
不要讓代理人共用服務帳號,每一個代理人都應該有獨立、可追蹤的身份,並且以「最小權限」為原則設計它的授權範圍,如果在 GCP 上開發,未來可以直接用 Agent Identity,如果還沒換過去,至少先確保代理人的行為有完整的操作紀錄。
- 代理人接觸哪些工具與資料?
將代理人會呼叫的所有 MCP server、API、資料表、SQL 查詢列出來,對每一個連接點問三個問題:
- 這個連接有沒有可能被惡意指令劫持?
- 如果代理人被誘導去存取不該存取的資料,影響範圍多大?
- 這個工具回傳的內容是否可信?
這裡特別提醒如果在做「自然語言轉 SQL 查詢」類型代理人的團隊,代理人生成的資料庫查詢是一條潛在的資料外流管道,建議在代理人與資料庫之間放一層審查機制(Model Armor 或自訂的查詢審查層),限制查詢範圍和欄位。
- 代理人如何處理外部內容?
如果代理人會讀取網頁、文件、email、使用者上傳的檔案,這些都是潛在入口,HONESTCUE 的案例告訴我們,現在的攻擊者已經會把惡意指令偽裝在看起來無害的內容裡,在設計任何需要讀取外部內容的代理人架構時,把「所有外部內容都是不可信的」當作預設假設。
- 代理人行為有被持續監控嗎?
傳統 DevOps 重視的是「程式碼部署之後還在正確運作嗎?」,代理式開發(AgentOps)要多問一個問題:「代理人的行為模式是否正常?」代理人突然存取某個平常不會碰的資料表、或對外連線到非預期的網域,這些都是需要告警的訊號,善用 Wiz、Security Command Center 等工具把代理人的運行狀態納入資安可視化平台,確保異常行為發生時能被及時發現。
從 DevSecOps 到 AgentSecOps:新的開發世代正在展開
如果說過去十年軟體開發界學到的一件事叫「DevSecOps」把資安思維從開發流程的末端,前移到每一個環節。那麼接下來十年的關鍵字可能會是「AgentSecOps」。
過去我們只要關心「程式碼安全」,因為程式碼的行為具備確定性與穩定性,但如今代理人不同,它會根據使用者輸入、外部內容、工具回傳值等動態即時做出決策,這代表資安思維必須從「事前審核靜態程式碼」擴張到「持續監控代理人行為」。
Google Cloud Next ’26 的 Agentic Defense 發佈,其實是在回答一個很根本的問題:當每家公司都要部署上千個代理人、當代理人彼此對話、當代理人代表使用者到外部世界做決定,我們需要一整套新的信任與治理基礎建設。
對開發者們而言,在享受代理人帶來的動態決策與創意性時,也需要意識到不穩定性帶來的挑戰,因為一樣的樂高積木,好人可以拼城堡、壞人可以打造武器;在如今的浪潮中,設計 AI Agent 不但需要思考「它能做什麼」,更需要將意識延伸至「不該做什麼、出事時如何及時止損」,在人人皆能開發、AI 大鳴大放的世代,這不僅是給資安團隊的作業,這是每一位開發者都該內建的思維。
(本文訊息由 CloudMile 萬里雲提供,內文與標題經 TechOrange 修訂後刊登。新聞稿 / 產品訊息提供,可寄至:[email protected],經編輯檯審核並評估合宜性後再行刊登。圖片來源:AI 生成。)



