




【我們為什麼挑選這篇文章】隔空玩俄羅斯方塊看起來很炫,但其實一切都是 AI 啊,看到這篇文章的時候只想說「我好興奮RRRRR」,附上一份完整教學,祝你過年確實擄獲親友的崇拜眼光(責任編輯:林子鈞)
本文經 AI 新媒體量子位(公眾號 ID:QbitAI)授權轉載,轉載請聯繫出處

假期模式已經開啟了~
學生黨已經賦閒在家,工業黨不少也已帶著橘子返鄉。
閤家歡樂,面對親朋的時候就要來了。
那麼,如何才能在鄉親們面前,顯得特立獨行、與眾不同?
你看這樣如何。
喧囂的人群之中,只見你端坐其間,面單不易察覺的微笑。
突然,你出手了!

手型撲朔變換,位置迷離轉移。
最新版喝酒划拳?不,他們很快發現,你神秘的手勢,竟然的控制著一個一個落下的彩色幾何圖形,完美的錯落疊加!對!你是神秘的俄羅斯方塊大師!
這麼傳統的遊戲,也能耍酷?當然,越是看似平淡,越能劍走偏鋒。
在那些打農藥、曬青蛙的軍團面前,你是如此的出眾。
套用某機構的話,那就是:
一樣的打遊戲,不一樣的酷?

最後,深吸一口氣,告訴鄉親們:這就是傳說中的——人工智能。
(眾人皆驚)
攝像頭 is all you need
這套俄羅斯方塊 AI 心法,今天就傳授於你。
心法源自一位名叫 Marianne Linhares 的 Medium 用戶。基於去年 Google 發佈的 Teachable Machine,她構建了一個 Demo,只需一個攝像頭,就能玩轉俄羅斯方塊。
先來介紹一下Teachable Machine。
Teachable Machine 本身是一個基於瀏覽器的工具,任何人(科學上網之後)都可以借助這個工具,使用電腦上的攝像頭,親手體驗如何訓練一個神經網絡。
無需代碼,只需電腦瀏覽器+攝像頭!
去年 10 月,量子位的李根同學在大理,親測表明:從一無所知到訓練完成,不超過 3 分鐘,而且還挺有意思。
方法很簡單,以科學的方式,打開這個頁面
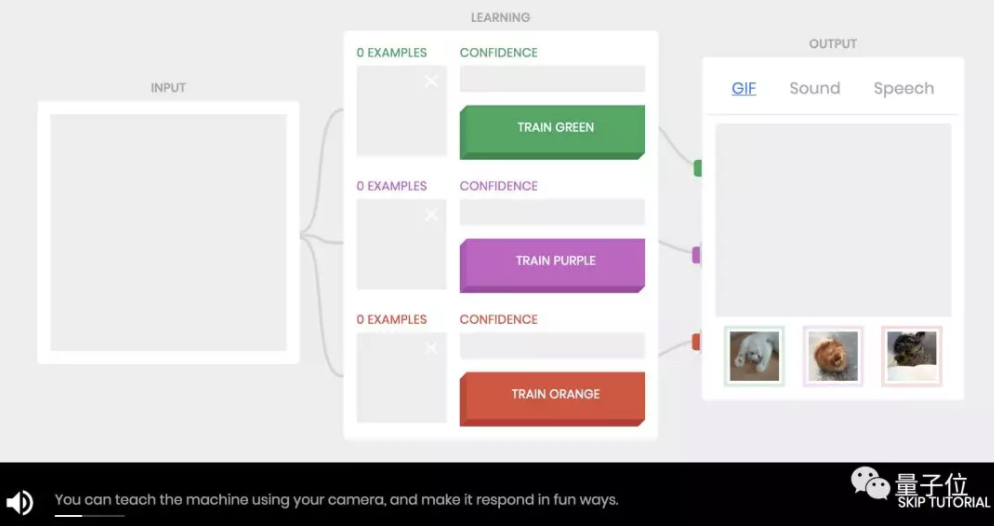
Teachable Machine 的神經網絡,能夠通過攝像頭,學會三個你發出的指令。整個訓練過程就是機器學習的三大步驟:輸入-學習-輸出。
1)輸入
在攝像頭前做某個動作,數量不低於 30 次,多些角度和場景,然後在「準確值」接近 100 時開始下一個動作輸入,總共三個。
2)學習
在你超過 30 次的動作捕捉中,機器通過這個「數據集」的學習,掌握了你這個動作代表的意思。
3)輸出
三個動作均按要求輸入完成後,一一對應的「輸出」也會在這個過程中學習完畢。你可以在屏幕前做出任一動作,機器會通過相機輸入後給出對應的「意義」。
當然,這個「意義」完全可以自定義,形式也多種多樣,比如 GIF 動圖、聲音,甚至某段回答。
這有段影片,詳細說明了這個過程。
get 凌空打遊戲神技
然後,說一下如何改造出一個用手勢凌空控制的俄羅斯方塊。
這項神技的基礎,就是讓計算機能通過攝像頭認出你的手勢,然後「翻譯」成遊戲中對應的按鈕,比如說上下左右。
這是一個圖像分類任務啊同學們!我們剛才講的 Teachable Machine,就剛好適合活學活用到這兒。
Google Creative Lab 還在 GitHub 上公開了它的一個樣板文件。別客氣,這些代碼拿去改!
關注人數並不多,可惜啊可惜,只能用俄羅斯方塊來拯救它了。我們可以在 Teachable Machined 基礎上構建一個模型,來識別各種手勢。

要讓機器能認識攝像頭拍到的手勢,我們的模型得能適應這些限制條件:
- 從用戶的攝像頭獲取輸入,就意味著我們事先不知道要將圖像分成哪些類。
- 由於我們事先不知道有哪些類別,就需要在瀏覽器裡直接訓練。
- 如果每個有電腦的人都能運行這個 demo 就好了,也就是說,它對計算力的要求不能太高。
- 要快。如果玩遊戲的時候該按左鍵還是右鍵都得花 5 分鐘來決定,那就不好玩了。
對於前三條限制,遷移學習是個好方法,拿一個在現實世界數千類圖像上訓練過,已經學會分辨形狀和邊緣的模型,再針對特定的數據稍加訓練。
Google Creative Lab 就是這麼做的,他們用了 SqueezeNet,這個模型的精度和AlexNet不相上下,大小卻不到 0.5 MB。
不過,怎麼用連我們自己都不知道什麼樣的數據,在瀏覽器裡重新訓練模型呢?
可以在SqueezeNet的其中一層插入一個 KNN(k-nearest neighbors)。KNN是基於實例的模型,因此,它不會執行明確的泛化,而是會將新的問題實例和訓練中見過的實例進行比較,也就沒有明確的訓練階段。
維基百科上是這樣描述KNN的:
k-NN是一類基於實例的學習,或者叫懶學習,它的函數只是局部近似,所有計算都會推遲到分類時。k-NN算法是所有機器學習算法中最簡單的之一。
對於我們的任務來說,簡直再合適不過了。
訓練
要訓練這樣一個模型來識別你的各種手勢,還有一些注意事項:
- 要用容易分辨的圖像;不幸的是,小細節不足以用來區分圖像。
- 各類圖像儘量用同樣的背景;如果你改了圖像背景,KNN學會去分辨的可能就是背景,忽略了目標本身。
- 目標要居中,而且要確保訓練模型辨認不同位置的目標,每個類別大約20-50個樣例就夠了。
Tips 講完,訓練正式開始。
我們訓練的目標,是讓模型將特定手勢與遊戲中的按鈕對應起來。

比如說握拳伸到畫面右端,就是向右;握拳放在畫面左側,就是向左;伸出大拇指,就是向上;手掌平放在桌面上,就是向下。
↑↓←→四個按鈕,就都有了。來測試一下:

作者提示:本文為向上選擇的手勢不太好,有時手勢從向左改到向右的時候,模型會誤認為看到了向上的手勢。用源代碼請小心。
最後,完成好的源代碼在這裡:
玩起來是這樣的,有時也會犯個小錯誤什麼的:

更多選擇,更多歡樂
上面,是本文所玩的俄羅斯方塊。實際上,同樣的心法,不止於俄羅斯方塊。
GitHub上這兩個遊戲也適合這種方法:
如果你覺得手勢還是不夠酷,還可以用更無厘頭的東西來訓練這個模型:

還有更炫酷的。
在 deeplearnjs.org 網站上,專門有一個 Cam Arcade。這個頁面收集了不少使用攝像頭+神經網絡可以訓練控制的經典遊戲。
包括《毀滅戰士》、《超級馬里奧》、《俄羅斯方塊》、《毀滅公爵 3D》。同樣的用法,也是使用攝像頭訓練,而且可調參數更多。
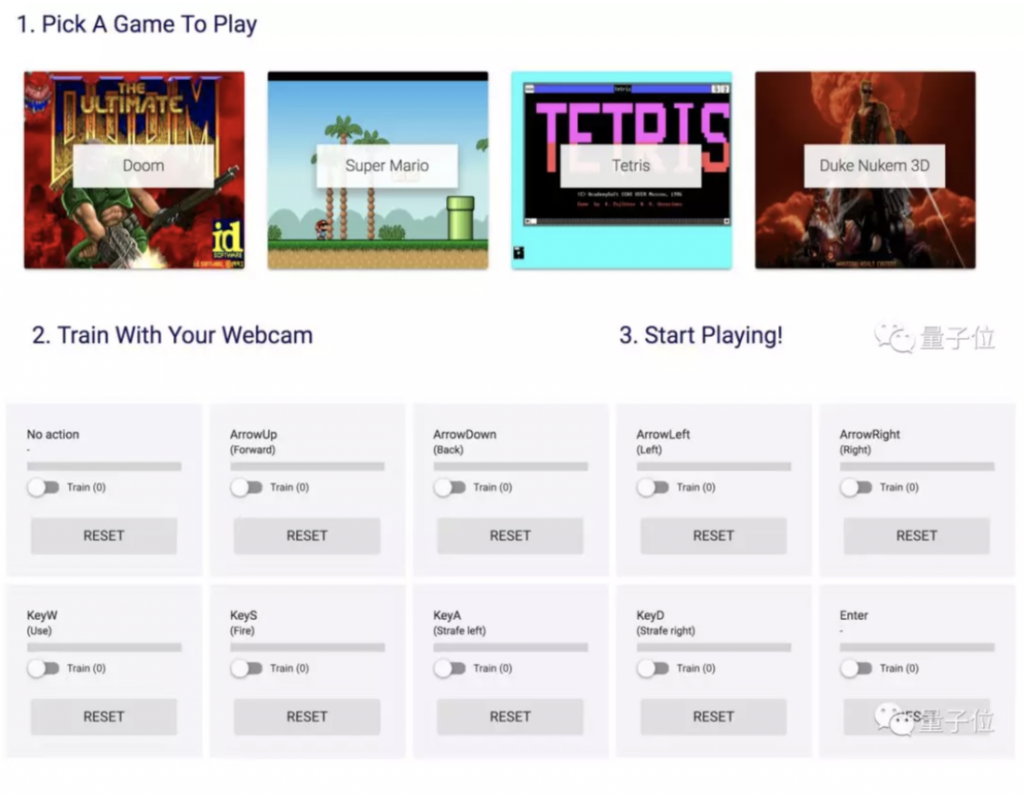
希望你訓練的開心。
提示:儘量用手勢,不要輕易嘗試上下左右晃頭,親測會暈。
最後,附送一個老遊戲的大集合。
不用翻牆,直接在瀏覽器玩。
不用翻牆、不用翻牆、不用翻牆……純玩。
–
AI 還能這樣用
【附學習資源】無人超市 AI 系統怎麼做?教你用影像辨識技術開一家 Amazon Go!
【不開無人店,一樣有競爭力】全家推科技概念店,第一次看到 AI 助理幫忙煮咖啡
【Reddit 上有開源檔】人人都可用 AI 作假 A 片,AV 女主角一鍵變臉神力女超人
(本文經 量子位 授權轉載,並同意 TechOrange 編寫導讀與修訂標題,原文標題為 〈一樣的打遊戲,不一樣的酷〉。)



