





【為什麼我們要挑選這篇文章】懂得教課的人,不一定會拍影片。線上教學課程要求影片、內容高品質,對某些教學者來說得耗費大量資源。
著名線上學習網站 Udacity 研究團隊,採用論文,進一步研發 AI 系統讓用戶只要傳音檔就能自動生成講課影片。此系統技術如何創造?本文解釋給你聽。(責任編輯:陳伯安)
「《科技報橘》徵才中!跟我們一起定位台灣產業創新力 >> 詳細職缺訊息
快將你的履歷自傳寄至 [email protected]」
線上課程已經成為了終生學習者們不可或缺的學習資源,而要完成一份高質量的影片,需要耗費不少人力和資源。尤其是在包含影片處理的時候,專業的講座影片片段處理需要的不只是工作室和設備,更重要的是轉化、編輯、上傳的每一節課程的原始影片素材。
最近,為瞭解決這一問題,Udacity 的研究團隊就嘗試將影片生產這一過程自動化。他們研究了一套 AI 系統,希望將音檔直接轉化為講座影片。
只要傳個語音就好,AI 會自動生成影像
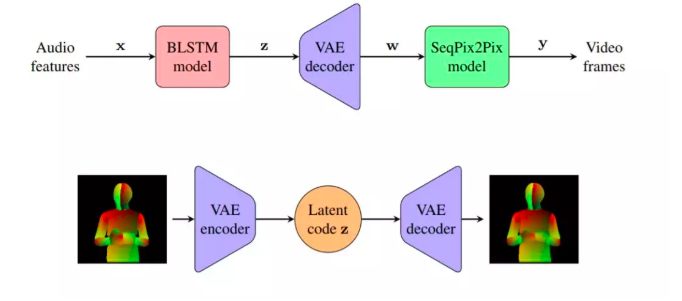
MOOC 平台上的內容生產可以是名利雙收,但是這些內容生產工作往往耗費大量時間。這就是為什麼 Udacity 的研究開發人員採用機器學習去自動將語音旁白生成講座影片。這一研究被發表在一篇名為LumièreNet: Lecture Video Synthesis from Audio的論文中。
在發表的論文中他們提到,通過直接定位語音文件和對應視角,機器學習框架LumièreNet可以合成任何長度的影片。

「在現行的影片製作中,AI 的參與或者半參與都能大規模實現影片生產的自動化,這將為靈活的影片內容發展提供巨大價值,因為不需要再去拍攝新的影片」,論文的作者說,「我們推行一種將任意長度的講座錄音去合成講座影片的新方法……一個簡易的、模塊化的、完全基於神經網路的系統。通過輸入演講音檔,就能得到對應的全身演講影片,這在之前還沒有從深度學習的視角被強調過。」
LumièreNet 的合成主要針對唇部周圍的面部表情,然後通過借用其他影片去合成畫面的其他部分。但是因為演講者的情緒不只是通過面部表情傳達,所以這個研究模型還有一個姿勢判斷組件,通過從影片框架訓練數據集中提取的數據合成身體特徵圖像。簡要來說,就是通過對身體主要幾個點的探測和定位,去創造真人演講的生動細節。還有一個模塊是關於雙向循環長短期記憶(BLSTM)神經網路,按正序或倒序處理數據,使得每一次輸出都能反映之前的輸入和輸出——它會利用輸入的語音特徵和目的去推測它們和視覺元素之間的關係。
機器學習研發新角度,但結果還稍嫌不足
為了測試 LumièreNet,研究人員拍攝了一個八小時的室內講座影片,產出了大概四小時的影片和兩段用於訓練和驗證的旁白。
研究人員報道說,通過訓練的 AI 系統可以生成逼真的影片片段,有流暢的身體動作和寫實的頭髮,但是這些結果在觀察者眼裡還是不能騙過觀察者的眼睛。
因為這些姿態評估器不能捕捉像眼球運動、嘴唇、頭髮、衣物之類的細節,被合成的演講者很少眨眼而且他們嘴巴的運動看起來有些不自然。
可以看到,在這一段合成的影片中人物的動作不夠生動,尤其是缺乏眼神上的交流。雖然嘴唇的開合與敘述幾乎完美同步,但是缺少更精細的運動細節。仔細看的話,會發現手指之間看起來模糊,更糟糕的是眼睛有的時候會看向不同的方向。
線上學習 AI 技術的下一步
研究團隊猜想,「面部要點」(例如,生動的細節)的添加或許能夠使合成變得更好。幸運的是,他們的系統模塊設計使得每一個組件都能被獨立訓練和驗證。
「許多未來的方向都是可被探索的」研究人員寫道,「即使最開始的時候只是用於支持靈活的影片內容發展。我們知道這項技術存在潛在的濫用行為……但是希望研究結果可以促進深度學習在商業影片生產領域的發展。」
(本文經合作夥伴 大數據文摘 授權轉載,並同意 TechOrange 編寫導讀與修訂標題,原文標題為〈给出音频AI就能生成对应演讲,Udacity想把线上课程录制自动化〉,首圖來源:Unsplash, CC Licened。)
延伸閱讀
6 週練出血洗星海爭霸的超強 AI!DeepMind 推出簡單、好學的機器學習新手菜單



