



前陣子中國廠商 DeepSeek 發表了自家的開源 AI 推理模型 R1,聲稱透過更便宜、更低耗能的訓練流程,達到媲美 OpenAI 的 o1 模型的頂尖效能;隨著 DeepSeek 議題在 AI 領域不斷發酵,關於它究竟為 AI 界帶來哪些創新、突破和風險的相關討論,至今顯然沒有停止的跡象。
除了最受外界關注,同時也是爭議最大、目前仍無法完全釐清的「低成本、高效率」之外,日前亦有資安專家特別針對 DeepSeek 提出警告,指出它將成為中國政府的「情報寶庫」,藉此打入民主國家的產業供應鏈,蒐集資料以研究西方企業的營運行為。
然而,在 AI 業界對 DeepSeek 一連串的爭論之中,有件重要且關鍵的事情,卻時常遭到許多人忽略,那就是 DeepSeek 身為開源項目的本質;舉例來說,有人質疑中國所開發的 DeepSeek 並非「真正的開源」,因為其訓練程式碼、資料集至今都尚未公開。
但是技術專家程世嘉卻直言,前述觀點事實上是一種「無知」;產業界人士亦指出,許多在西方民主國家擁有重要地位的 AI 公司,例如 Meta、Databricks、Mistral、Hugging Face 等,皆因為 DeepSeek 的橫空出世而有所受益。
DeepSeek 讓開源 AI 更有「說服力」
自 2022 年 11 月 OpenAI 發表 ChatGPT 問世以來,AI 研究人員一直在努力改進、創新大型語言模型技術的各種進步,而開源 AI 更是許多廠商關注的重要領域。
無論是 Meta 這類資本雄厚的科技巨頭,或者如 Mistral、Hugging Face 等新創公司,過去一直以來都押注開源社群改進旗下 AI 技術,同時向業界廣泛分享各種成果和進展。
部分科技業高層認為,中國 DeepSeek 所展現出來的突破,既不亞於 Meta 等企業過去所做的貢獻,更會讓開源 AI 模型在未來變得更有「說服力」。
AI 新創公司 NetMind 的首席商務官 Seena Rejal 就指出,DeepSeek 成功向外界表明,所謂的開源 AI 不再只是非商業性的研究計劃,更是一種可行的、可擴展的封閉模型替代方案,後者最知名的例子即是 OpenAI 的 ChatGPT。
並非中國超過美國,而是開源追上私有
Seena Rejal 說,DeepSeek R1 證明了即使是開源模型,同樣可以擁有最為先進的性能,媲美 OpenAI 和其他公司的私有模型,更對打破了只有閉源模型才能主宰 AI 領域的既有概念。
旗下擁有 Llama 開源模型的 Meta 首席 AI 科學家 Yann LeCun 更直言,外界對 DeepSeek 驚人表現的深入解讀,不應該是「中國贏過了美國」,而是「開源模型正在超越專有模型」。
Yann LeCun 說,DeepSeek 從其他開源模型和開放性研究,例如 Meta 的 PyTorch 和 Llama 中獲得資源,並使該公司進一步發起創新,再將最終成果以開源模式分享出來,使更加廣泛的 AI 社群能夠從中獲利,這就是「開源」所展現出來的驚人力量。
程世嘉:說 DeepSeek 不是開源太無知
然而,至今依然有人質疑 DeepSeek 並沒有達到真正的開源,畢竟除了權重(Weight)及論文之外,包含訓練程式碼、資料集,仍握在 DeepSeek 公司手上,對此台灣新創公司 iKala 共同創辦人暨執行長程世嘉特地撰文批評,上述想法「真是有夠無知」。
程世嘉指出「AI 模型最重要的就是權重」,並表示業者一旦將權重開放出來,後續幾乎就能做到任何事情,例如效能優化、架構改進、模型分析和部署整合等多個層面,同時這些項目也是「真正的 AI 從業人員」最為關心的面向。
程世嘉說,開放權重對於效能優化帶來的核心價值,在於讓工程師能夠透過分析真實的權重數據,進一步制定更加精準的優化策略。
外界目前對於 DeepSeek 最主要的爭議點,程世嘉認為,依然在於模型訓練成本,是否真的如同該公司所言如此低廉;程世嘉表示,關於這點他覺得 DeepSeek 較高機率帶有誇大成分,不過還是無法跟「不是開源 AI 模型」這件事混為一談。
開源 AI 所付出的代價:安全
雖然開源 AI 社群因為 DeepSeek 的出現而士氣大振,但開源 AI 本身確實也有缺點。舉例來說就有資安專家警告,雖然開源技術對於創新領域是件好事,但同時也讓 AI 服務更容易受到攻擊,畢竟任何人都有權利,將開源 AI 模型重新修改、重新包裝。
此外,通訊領域巨頭 Cisco 旗下的 AI 安全研究團隊也表示,近日他們透過十分成熟的「演算法越獄技術」,讓 DeepSeek R1 對 HarmBench,即測試模型安全性的所使用的標準化紅隊工具,所發出的一連串有害提示做出回應,攻擊成功率高達 100%。
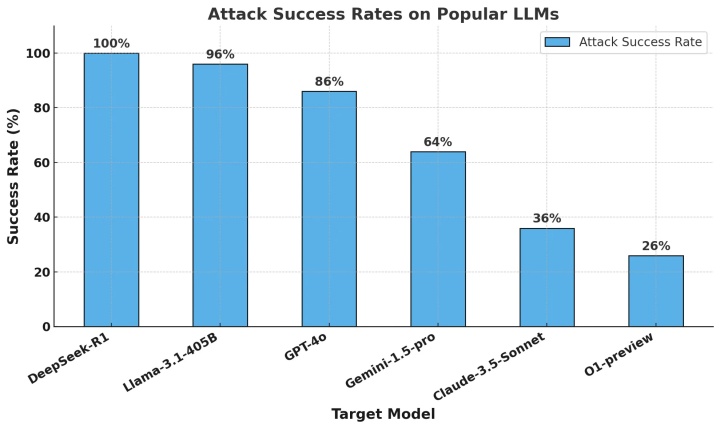
Cisco 研究人員指出,即便 DeepSeek R1 聲稱使用了更低的成本進行開發、訓練,但從資安的角度來看,它卻付出了不同的「代價」,那就是 AI 模型本身的安全性,以及對使用者的保障。
網路安全公司 Proofpoint 安全策略師 Matt Cooke 也表示,就跟其他 AI 服務一樣,DeepSeek 對於企業和個人都是一把雙刃劍,雖然其創新潛力不可否認,資料外洩風險仍是重大問題,尤其是透過 DeepSeek 網站、服務所處理的資料,基本上都會被傳輸到中國,進一步引發了擔憂。
擺脫矽谷依賴,主權 AI 推開源一把
在美國貿易戰的背景之下,由於中國廠商難以取得訓練、執行 AI 模型所需要的先進晶片,因此不少業者轉而投入開源技術,提升旗下 AI 模型的吸引力;包括 DeepSeek 在內,許多中國公司正大力追逐開源社群,希望藉此增加創新動力,並推廣 AI 模型獲得採用。
中國在開源 AI 領域的投入,讓其他國家開始試圖跟上,例如在歐洲,一個由學術界、企業和資料中心組成的聯盟,已經合作開發了出一系列高性能、多語言的大型語言模型 OpenEuroLLM。
開源 AI 發展獲得強烈關注,不只是因為 DeepSeek 及 Meta 等公司的投入,還是各國發展主權 AI 的關鍵部分;許多國家都希望藉由投資境內的 AI 實驗室和資料中心,發展自有模型,減少對美國和矽谷科技企業的依賴。
【推薦閱讀】
◆ 專家警告 DeepSeek 隱私保障「一片空白」,資料收集量比 Google 高 20 倍



