當 Anthropic 因美國出口管制調整 Claude Fable 5 與 Mythos 5 的公開存取政策後,一個過去較少被討論的問題浮現:如果企業的關鍵 AI 能力建立在單一模型供應商之上,當政策、商業策略或地緣政治發生變化時,企業是否有能力維持系統穩定運作?
就在這個時間點,日本 AI 新創 Sakana AI 發表多模型編排系統(Model Orchestration System)Fugu。與其說這是一個新的大型語言模型,不如說它是一套負責協調不同模型合作的「AI 指揮系統」。Sakana AI 希望證明,透過多個模型組成的 Agent 群協同運作,即使不擁有最強大的單一模型,也能在部分任務上達到接近甚至超越前沿模型的表現,並且無需承擔出口管制的風險。
不是更大的模型,而是會調度模型的模型
根據 Sakana AI 官方說明,Fugu 的核心並不是又一個試圖包辦所有任務的大型語言模型,而是「編排模型」(orchestration model)。Fugu 被訓練來調用一個「可隨時抽換的代理池」,當收到複雜請求時,它會自行判斷是直接回答,還是把問題拆解、委派給多個專家模型,再驗證並整合出最終輸出。
對開發者而言,這整套多代理協作被隱藏在單一且相容 OpenAI 的 API 之後,多代理系統的複雜度不會進到程式碼裡。Sakana 在技術說明中提到,Fugu 本身就是一個被訓練來調用代理池中各種大型語言模型的語言模型,甚至能遞迴地調用自己。
這也是 Fugu 與一般「模型路由」的差異。據《VentureBeat》報導,路由平台如 Not Diamond、Martian 或開源的 RouteLLM 等,做的是一次性決策:分析提示後,預測哪一個單一模型最合適,再把整個查詢分派過去,像個只負責調度的空中交通管制員。Fugu 則更接近 Router-R1(NeurIPS 2025)這類多輪系統,會把任務拆解、邊推理邊委派,讓多個模型並行或接力處理後再整合輸出。簡單來說,路由是「挑一個模型來用」,編排是「拆任務、調度多個模型分工」。
這套設計奠基於 Sakana 2026 年的兩篇研究 TRINITY 與 Conductor:系統以學習而來的協調策略、而非人工設計的固定流程,自主管理模型選擇與驗證的整個生命週期。
Sakana 共同創辦人暨執行長 David Ha(曾任職 Google Brain)在 X 上的貼文中將 Fugu 定位為比任何單一模型供應商更可靠的企業選項,並寫道:「編排模型才是下一個前沿,超越更大的模型。」
Sakana 提供兩個版本:標準版 Fugu 主打低延遲、適合日常互動與寫程式等任務;旗艦版 Fugu Ultra 則針對 AI 研究、資安分析、多步驟專利調查等高難度工作,調度更深的專家池。
Fugu 能打敗前沿模型嗎?效能數字怎麼說
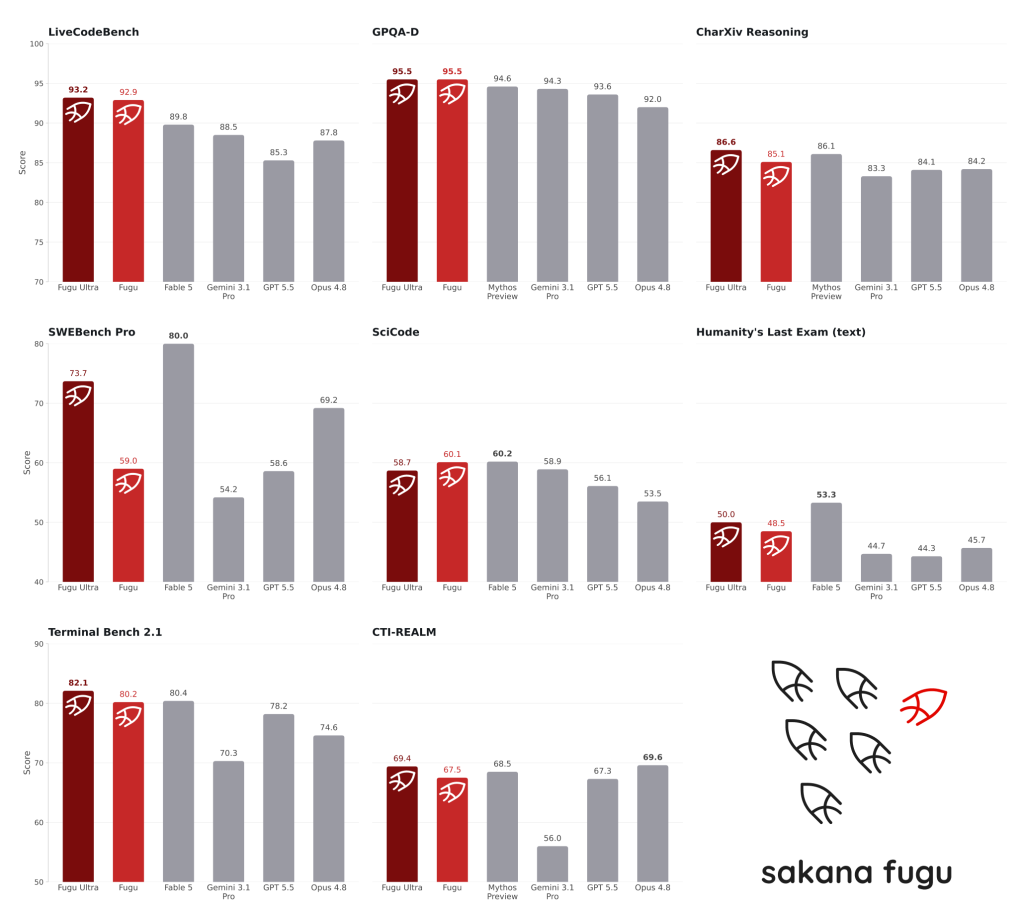
為了驗證多模型協作的效果,Sakana 公布了多項基準測試結果,並表示在業界最嚴苛的工程、科學和推理基準測試中,與 Anthropic 的 Fable 5 和 Mythos Preview 等領先模型並駕齊驅。根據官方數據,Fugu Ultra 在 LiveCodeBench 程式能力測試中獲得 93.2 分,高於 Claude Fable 5 的 89.8 分;在 GPQA Diamond 科學推理測試中則達到 95.5 分,略高於 Mythos Preview 的 94.6 分。
在 SWE-Bench Pro 等軟體工程測試中,Fugu Ultra 也優於 GPT-5.5 與 Claude Opus 4.8。Sakana 因此宣稱,Fugu Ultra 已具備接近 Frontier Model 的能力水準。
不過,《VentureBeat》也指出,Fugu 並非在所有測試中都取得領先。例如在 Humanity’s Last Exam 與 SWE-Bench Pro 等部分測試項目中,Anthropic 的 Fable 5 仍維持優勢;而在長上下文能力與資安相關測試中,GPT-5.5 與 Claude Opus 4.8 也各自在特定項目保持領先。
具體的取捨在開發者實測中更清楚。據《VentureBeat》報導,創意公司 Mark Studios 負責人 Mark Santos 同時要求 Fugu Ultra 與 Claude Opus 4.8 用 Three.js 打造一款「Crossy Road」遊戲:Fugu Ultra 在 22 分鐘內以約 8.9 萬 token、約 7.32 美元完成,但成品有方向反轉、鏡頭角度怪異等小瑕疵;Opus 4.8 則耗時 79 分鐘、燒掉約 94 萬 token、近 37.85 美元,中途還一度卡在重試迴圈需人工介入,但最終做出的應用設計與功能性較佳。Santos 的結論是,論應用的功能、品質與設計,Opus 勝出;論速度與效率,則是 Fugu 勝出。
AI 主權、供應鏈備援與新的基礎設施層
《VentureBeat》報導指出,Box 執行長 Aaron Levie 認為,隨著閉源與開源前沿模型持續推陳出新,未來將有大量價值集中在能夠有效進行模型路由與編排的中介層。
但雲端開放 AI 基礎設施商 Prime Intellect 研究工程師 Elie Bakouch 則提出不同看法。他認為,Fugu 本質上仍建立在封閉模型之上,使用者無法掌握底層究竟使用哪些模型,也無法完全控制其運作方式,因此未必能直接等同於真正的 AI 主權。
《VentureBeat》觀察,Fugu 的重要性不在於又出現一個更強大的模型,而是在於它提出另一種可能性。當企業同時使用 GPT、Claude、Gemini、DeepSeek、Qwen 與各種開源模型時,未來決定效能、成本與風險控管能力的關鍵,可能不再是模型本身,而是背後那層負責協調與編排的系統。
【推薦閱讀】
◆ Anthropic 被迫關閉 Fable 5、Mythos 5:美國經濟學家 Tyler Cowen 警告,全球可能轉向中國 AI
*本文開放合作夥伴轉載,資料來源:Sakana AI、《VentureBeat》、《Bank Info Security》,首圖來源:Sakana AI