



IDC 預測,2025 年全球 AI 支出將達 2270 億美元 ,2030 年則將超過 19.9 兆美元,創造全新的 AI 經濟。當 AI 應用的需求正在快速成長,落實人才培育、追求突破性解決方案,正是持續推升 AI 發展的關鍵動能。面對這樣的趨勢,國家高速網路與計算中心(NCHC)與 NVIDIA、OpenACC 共同主辦「NCHC Open Hackathon」(Open 黑客松)競賽,在為期 3 週密集的實作活動中,不僅匯聚來自全台各地的精英團隊,更成為學子、開發者們實現 AI 創新、進化 AI 技術的最佳平台。
這場「NCHC Open 黑客松」已持續多年,本期吸引 24 支隊伍報名參賽,經篩選後共有 12 支團隊入圍決賽。在競賽過程中,各團隊以 NCHC 提供的 DGX-A100 與國際 Open Hackathon 組織的 DGX-H100 超級電腦為基礎,共同探索運算效能的極限,展現驚人技術成果。
加速推理 LLM、優化 AI 模型部署與推論,開創 AI 應用新效益
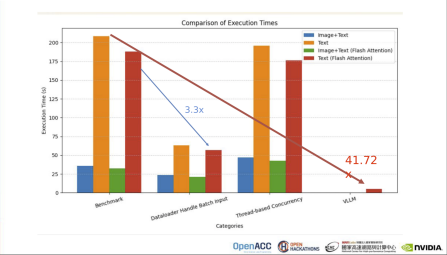
「在暑假參加 NTHU x NCHC HPCAI Camp 時,我們聽到 NVIDIA 的資深解決⽅案架構師李正匡 CK Lee 的演講,才⾸次認識 Open Hackathon 這項活動,」來自國立陽明交通大學蔡孟勳教授實驗室的「NYCU HPC team2」團隊分享,隨著⼤型語⾔模型需求快速增⻑,必須加速推理,才能持續拓展對話系統、搜尋引擎等即時應⽤,並減少 GPU 使⽤時⻑,進⼀步降低電⼒與硬體資源消耗。在參賽前期,最初團隊決定使⽤ Google 開發的 Flax 框架加速模型推理,然而卻面臨在 Flax 框架下重新編寫⼤型語⾔模型、將 PyTorch 模型權重轉換為 Flax 模型權重等高難度技術工作,因此在與 NVIDIA DevTech GPU 開發技術工程師王詩杰討論後,團隊決定轉向 PyTorch 框架,逐步探索如何優化模型推理。最後,借力 Flash Attention、KV Cache、Batch Inference 等技術並引⼊了 vLLM 框架,NYCU HPC team2 團隊成功讓 NVLM 同時處理四個問題純⽂字的輸⼊加速 330%、同時處理六個圖⽚問題的速度提升 156%,推動技術飛躍成⻑。
(更多資訊: https://github.com/nqobu/nvidia/tree/main/20241204)
來自國立臺灣大學生物機電工程系郭彥甫教授機器視覺與機器學習實驗室的「Plantmen」團隊,則將高效能運算(High-Performance Computing)技術,應用在優化 AI 模型部署與推論,並特別開發名為「Plantmen」的農業病蟲害 AI Agent,結合影像辨識與自然語言生成技術,提供自動化病蟲害辨識與即時諮詢服務,嘗試將生成式 AI 技術帶入生活化的應用場景。「我們發現 Plantman 的文件搜尋與文本生成過程所需的計算量過於龐大,導致使用者需要等待數 10 秒才能收到完整回覆,大幅影響使用體驗,」團隊分享,一開始他們嘗試使用 TensorRT 和 TensorRT-LLM 函式庫優化模型,以縮短使用者等待回覆的時間,然而由於團隊在進行模型轉檔、調整關鍵參數等面向缺乏經驗,因此時常遇到錯誤。後來在競賽過程中,團隊將重點改為利用 TensorRT 技術縮短推論時間,並成功將端到端推論速度提升超過 10 倍,讓加速後的 Plantman 系統能在約 3 秒內完成病蟲害資料搜尋與文本生成,大幅改善使用體驗。
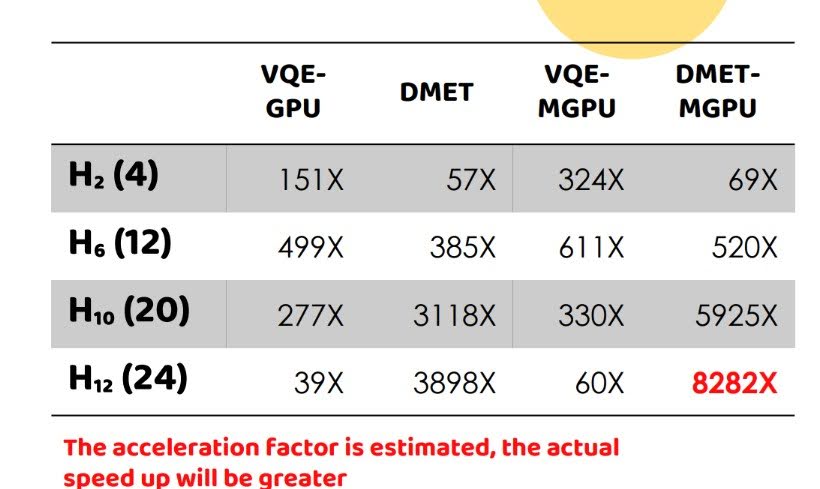
將量子模擬計算結合 GPU,成功創造近 10,000 倍的加速效果
在以「量子模擬計算」為主題的隊伍中,由來自國立臺灣大學、國立陽明交通大學、國立臺灣師範大學、國立政治大學、中原大學等多個實驗室與學術單位成員共同組成的「NoLab」,選擇深入探討「變分量子本徵值求解器(VQE)」,並使用量子化學模擬中常見的 DMET(密度矩陣嵌入理論) 演算法嘗試大幅降低計算量、提高量子模擬效率。「但是我們一開始對 DMET 的數學原理理解不足,所以在建構演算法的初始階段遭遇許多瓶頸,」NoLab 團隊分享,為解決這個問題,部分組員專注於研究 DMET 的核心數學方法,另一些組員則探索既有案例,並發現 OpenQEMIST 項目是一個可以快速實現 DMET 的絕佳工具。最終,NoLab 團隊在深入研究後,決定以 NVIDIA CUDA-Q 工具鏈為基礎,不僅使 DMET 演算法成功在 GPU 上運行,更進一步實現了多 GPU 的並行化計算,達成相較 CPU 加速達 8,282 倍以上的卓越成果,大幅展現硬體加速的潛力,也開啟團隊對未來量子計算應用的更多想像。
此外,由中原大學助理教授張晏瑞、主任張慶瑞共同帶領的「CYCU_Quantum」團隊,長期對高效能運算與加速器技術懷抱高度興趣,因此期待透過這場競賽過程,將量子相關的計算模式結合 GPU 加速運算,以解決實際的科學計算問題。在參賽過程中,CYCU_Quantum 團隊遇到的最大挑戰,就是如何高效將量子隨機隨機行走(Quantum Stochastic Walk)的運算映射至 GPU 架構中,因為 Quantum Stochastic Walk 與一般傳統計算方式不同,必須考量算符(Operator)的疊代與矩陣運算的特性,因此在 NVIDIA Quantum Solution Architect 量子模擬解決方案架構師王勻遠、量子演算法工程師濵村 一航與 DevTech GPU 開發技術工程師孟祥雲的建議下,團隊使用 operator sum 的方式分解計算問題,成功在 GPU 上達到近 10,000 倍的加速效果。

探索加速運算為氣候變遷與生命科學帶來的創新突破
除了在生成式 AI 與量子模擬計算領域尋求運算技術突破外,在與每個人生活切身相關的氣候變遷與生命科學主題,也是高效能運算的應用藍海。陳律閎、鄧君豪兩位國立中興大學應用數學系副教授共同帶領的「氣象署──興大應數聯隊」,由李尚恩、陳廷安、陳建河、劉邦彥共同組成。團隊分享,氣象署作業中的全球預報模式 CWAGFS-TCo 動力核心計算部分已經完成 GPU 移植,但物理參數化的計算仍完全仰賴 CPU 計算,使得物理參數法計算佔整體計算時間約 90%,形成主要瓶頸。面對這樣的狀況,團隊決定使用 OpenACC 展開 GPU 移植,卻常因不熟悉資料傳輸規則與同步指令的作業流程情況下發生錯誤,後來在試錯過程與團隊導師的經驗分享中,團隊也回顧先前已進行 GPU 移植的大氣重力波(GWD)物理參數化法、大氣臭氧(Ozone)物理參數化法計算,並成功改進演算法,大幅減少 Ozone 計算量,讓加速比更高達 417 倍。

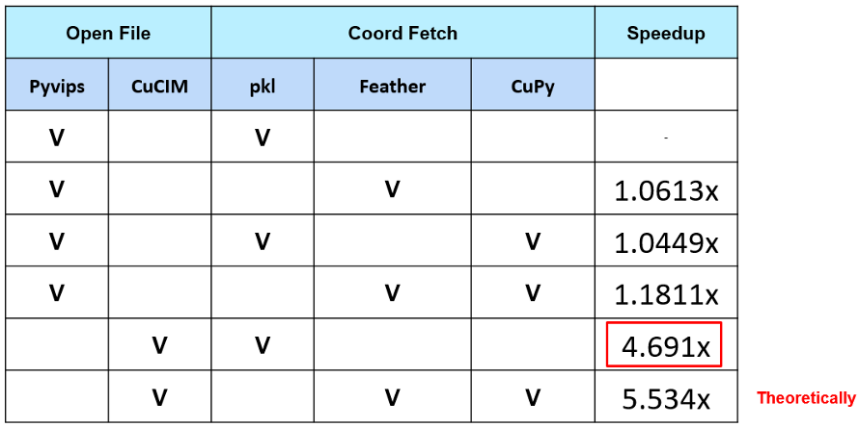
另一方面,當 AI 與醫療影像分析的結合越來越密切,卻也因為資料隱私問題讓跨機構資料共享面臨挑戰。觀察到此一現象的成功大學「smile lab」團隊,決定採用「聯邦式學習」技術,讓各機構可以在不洩露資料的前提下共同訓練模型。為了提升模型訓練的彈性與精確度,團隊將 WSI 的裁切流程整合至訓練過程中,允許根據需求隨時取得不同倍率與任意區域的影像資料,卻也帶來影像處理耗時過長的問題,最後,smile lab 團隊嘗試更換 Feather 格式與使用 CuPy ,成功達到讓資料讀取時間減少約 30%、加速影像裁切運算速度約 40% 的成果。
從構思到實作,「NCHC Open Hackathons」期待培養參賽團隊解決問題的能力,並為參賽成員積累應用 HPC SDK、CUDA-Q、CuPy、cuCIM 等技術的寶貴經驗,同時透過 NCHC、NVIDIA、OpenACC 三方資源的加乘,為台灣人才培育、學研界技術研發,以及加速運算的應用場景,開啟無限可能。
想深入了解更多黑客松團隊的故事,請點擊連結。



